Open-Source MLOps — Fra lokalt til skyen!
Hvis du har jobbet med maskinlæring, har du sikkert følt på frustrasjonen over å holde styr på flere maskinlæringseksperimenter — huske parametere, spore resultater, eller finne ut hvilken modell som presterte best. Å strukturere maskinlæringsprosjekter kan være utfordrende, spesielt ettersom Machine Learning Operations (MLOps) fortsatt er et nytt og voksende felt som kan være vanskelig å navigere. I denne artikkelen skal vi sette opp en enkel pipeline for modelltrening og eksperimentsporing ved hjelp av open-source verktøyet MLflow. Denne skal vi deploye i skyen, på en slik måte at vi til enhver tid har tilgang til den beste maskinlæringsmodellen, som vi enkelt kan benytte oss av i applikasjonene våre. Ved å investere tid i å sette opp en god flyt for MLOps, legger man grunnlaget for et mer effektiv og skalerbart arbeid med maskinlæring, som hele teamet kan dra nytte av!


MLOps handler om å kontinuerlig og automatisk trene, evaluere og monitorere maskinlæringsmodeller. Dette gjør vi ved å låne prinsipper fra mer typisk DevOps, og benytte oss av disse i utvikling- og testflyten av maskinlæringen vår. Å komme i gang med en mer oversiktlig pipeline for modellutvikling er enklere enn man skulle tro. Vi skal benytte oss av open-source verktøyet MLflow, og deploye det til Google Cloud (I dette eksempelet bruker vi Google Cloud, men prinsippene gjelder uavhengig av hvor du deployer applikasjonen din 😁 ).
Koden som brukes som eksempel kan sees i mer detaljer i dette Github repoet.
Hva bruker vi MLflow til?
For de av dere som har jobbet noe med maskinlæring, har dere sikkert opplevd hvor lett det er å miste oversikten over hva dere til enhver tid har testet. Det blir raskt et behov for bedre struktur, logging og versjonering av modelltreningen. Her kommer MLflow inn som et nyttig verktøy. Det gir oss enkel oversikt over modellkjøringer, hvilke parametere som ble brukt under treningen, og treningsløpene som har gitt de beste resultatene.
Gjøre klart for trening i skyen
Det går fint an å jobbe med MLflow lokalt, men dersom man ønsker å dra mest nytte av verktøyet, gjelder det å tilgjengeliggjøre modellkjøringene for resten av teamet. Her er det to ting vi må ta hensyn til.
Den første er at MLflow bruker en database for å håndtere data fra eksperimenter. Dette er parametere vi lagrer, modell-versjoner, og evalueringsmetrikker. Det gjør at vi kan sammenligne modeller i applikasjonen vår, og finne igjen hvor vi har lagret den beste modellen. For eksperimentdataene oppretter vi en PostgreSQL-instans, en databasebruker og selve databasen.
gcloud sql instances create INSTANCE-NAME \
--database-version=POSTGRES_15 \
--region=eu-west1 \
--tier=db-f1-micro \
--storage-type=HDD \
--storage-size=10GB \
--authorized-networks=0.0.0.0/0
gcloud sql users create USERNAME \
--instance=INSTANCE-NAME \
--password=PASSWORD
gcloud sql databases create DATABASE-NAME --instance=INSTANCE-NAMEDen andre tingen man trenger er et sted å lagre større filer, eller modellartifakter. For dette oppretter vi en bøtte i Google Cloud Storage. Her lagres selve modellen, men også fysiske filer som prediksjoner på testdata som vi lagrer etter trening. I denne bøtten må vi opprette en mappe som heter /mlruns. Her vil alle modellartifaktene lagres.
gcloud storage buckets create gs://BUCKET-NAMEI tillegg må vi ta hensyn hvor vi skal deploye MLflow serveren, noe som avhenger av plattformen som benyttes. I Google Cloud skal vi benytte oss av Cloud Run for hosting. Vi oppretter et eget artifact repository hvor vi kan lagre Docker-image som vi senere skal pushe til skyen.
gcloud artifacts repositories create ARTIFACT-REPO-NAME \
--location=eu-west1 \
--repository-format=dockerDette var de viktigste tingene å få på plass før vi kan forsøke å deploye MLflow serveren. Avhengig av hvordan man velger deploye applikasjonen, kan det være nødvendig å konfigurere tilganger for å lese og skrive til databasen og bøtten. For en mer omfattende gjennomgang av dette i GCP kan man ta en titt på denne blogposten.
Deploy MLflow serveren
Nå som vi har et sted å hvor backendet serves (postgres databasen) og modell-artifaktene lagres (storage bøtten), kan vi definere applikasjonskoden vår. Dette er så enkelt som å starte serveren og å referere til henholdsvis Postgres- og Storage URLen.
print(f"Upgrading MLflow database schema at {POSTGRESQL_URL}")
subprocess.run(["mlflow", "db", "upgrade", POSTGRESQL_URL])
print(f"Starting MLflow server on port 8080 with backend store {STORAGE_URL}")
subprocess.run([
"mlflow", "server",
"--host", "0.0.0.0",
"--port", "8080",
"--backend-store-uri", POSTGRESQL_URL,
"--artifacts-destination", STORAGE_URL
])Dockerfilen for å deploye MLflow skriptet installerer nødvendige system-avhengigheter for å støtte MLflow og maskinlæringsbiblioteker. Den setter Python scriptet vår som entry point, og starter serveren slik at miljøet er klart for å logge og spore modelltreningene.
FROM python:3.12-slim
RUN apt-get update && apt-get install -y \
pkg-config \
libhdf5-dev \
gcc \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8080
CMD ["python", "run_mlflow.py"]For å få serveren til å kjøre i Google Cloud Run, bygger vi og pusher Docker-imaget, som vi deretter refererer til når vi deployer Cloud Run Containeren.
Bygg og push MLflow Docker Image:
docker buildx build --platform linux/amd64 --load -t europe-west1-docker.pkg.dev/PROJECT-NAME/REPO-NAME/mlflow-server:latest .docker buildx build --platform linux/amd64 --load -t europe-west1-docker.pkg.dev/PROJECT-NAME/REPO-NAME/mlflow-server:latest .Deploy MLflow server:
gcloud run deploy mlflow-server \
--image=europe-west1-docker.pkg.dev/PROJECT-NAME/ARTIFACT-REPO-NAME/mlflow-server:latest \
--region=europe-west1 \
--platform=managed \
--service-account=SERVICE-ACCOUNT \
--memory=1Gi \
--port=8080 shGratulerer! Du har nå en MLflow instans kjørenes i skyen, som hele teamet ditt kan benytte seg av! 🎉 For de som foretrekker å skrive infrastrukturen som kode, i stedet for å benytte seg av Google Cloud CLI, ligger tilsvarende oppsett med Terraform i Github Repoet.
Versjonshåndtering av ML-treninger med MLflow
Nå som vi har en MLFlow instans vi kan dele på i teamet, kan vi også begynne å koble treningene våre opp mot denne.
Modelltrening i skyen
Å kjøre MLflow serveren lokalt vil automatisk en /mlruns mappe i din mappestruktur. For å bruke serveren i skyen, må vi derimot referere til serveren sin tracking URI spesifikt.
import mlflow
MLFLOW_TRACKING_URI = “URL til din MLFlow server”
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)Uavhengig av om treningen skjer lokalt på din PC, eller deployes til en egen jobb i skyen, vil alt du logger og lagrer gjennom MLflow, nå kunne lagres gjennom MLflow instansen i skyen!
Hvordan fungerer versjonshåndtering med MLflow?
Med MLflow kan du bruke ditt foretrukne maskinlæringsbibliotek. MLflow fungerer som en innpakning rundt modelltreningen, og er lett å implementere med allerede eksisterende kode. Vi tar utganspunkt i en enkel Keras modell, og plasserer den innenfor en MLflow kjøring, slik at vi kan lagre modellen etter treningen er ferdig.
import mlflow
from mlflow.models import infer_signature
MLFLOW_TRACKING_URI = "URL til din MLFlow server"
EXPERIEMENT_NAME = "Navnet på eksperimentet"
x_train, y_train, x_test, y_test = load_data()
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
mlflow.set_experiment(EXPERIEMENT_NAME)
with mlflow.start_run() as run:
model = LSTMModel(x_train, y_train)
model.train()
mlflow.keras.log_model(model, "lstm_model")Foreløpig har vi ikke gjort mange endringer, annet enn at vi laster opp modellen til skyen etter vi er ferdige med treningen. Dette er en god start, men dersom vi skal benytte oss av denne senere (noe vi naturligvis ønsker), så gjelder det å holde litt bedre styr på modellversjoner og metrikker. Vi utvider koden med et modellregister, hvor vi skal lagre de forskjellige modellversjonene.
import mlflow
from mlflow.models import infer_signature
MLFLOW_TRACKING_URI = "URL til din MLFlow server"
EXPERIEMENT_NAME = "Navnet på eksperimentet"
MODEL_REGISTRY_NAME = "Treninger i samme register blir evaluert mot hverandre"
x_train, y_train, x_test, y_test = load_data()
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
mlflow.set_experiment(EXPERIEMENT_NAME)
with mlflow.start_run() as run:
model = LSTMModel()
model.train()
mlflow.keras.log_model(model, "lstm_model")
predictions = model.predict(x_test)
accuracy = calculate_accuracy(y_test, predictions)
result = mlflow.register_model(f"runs:/{run.info.run_id}/model", MODEL_REGISTRY_NAME)
mlflow.log_metric("accuracy", accuracy)
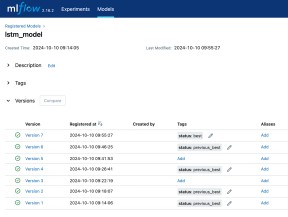
compare_and_update_models(accuracy, MODEL_REGISTRY_NAME)Etter trening regner vi ut en eller flere metrikker, som vi logger sammen med modellkjøringen. Dette er med på å avgjøre hvilken modell som vi anser å være den beste. I et produksjonssystem ønsker vi naturligvis å benytte oss av det som til enhver tid er den beste modellen for vårt bruksområde. Med MLFlow, kan vi dynamisk holde styr på dette ved å sammenligne modellers metrikker opp mot hverandre, og tagge den beste modellen slik at vi kan finne den igjen senere. Vår første modell i et modellregister kan vi gi taggen “best”. Hvordan skal vi finne igjen denne? Jo, vi kan søke gjennom modellregisteret, og finne modellenversjonen som har blitt gitt denne taggen, og samtidig hente ut presisjonen som vi logget tidligere:
def get_best_model_version(model_registry_name, key="status", value="best"):
model_versions = mlflow.search_model_versions(filter_string=f"name='{model_registry_name}'")
for version in model_versions:
if version.tags.get(key) == value:
run = mlflow.get_run(version.run_id)
accuracy = run.data.metrics.get("accuracy")
return version, accuracy
return None, NoneDenne metoden gjør at vi får hentet ut både versjon og presisjon på fra den foreløpig beste modellen, dersom den finnes. Denne kan vi bruke for å sammenligne med de nye resultatene vi får når vi kjører en ny trening. Dersom den nye modelltreningen vår gir bedre resultater på de metrikkene vi ønsker å evaluere opp mot, kan vi sette denne til å få taggen “best”. Deretter oppdateres den gamle modellen med en ny tag som indikerer at modellen vår på et tidligere tidspunkt har vært den beste. På denne måten kan vi holde styr på hvilken modell vi ønsker å benytte oss av, og hvilke modeller vi eventuelt skal falle tilbake på om det blir nødvendig.
def compare_and_update_models(accuracy, model_registry_name):
client = mlflow.tracking.MlflowClient()
best_model_version, best_model_accuracy = get_best_model_version(model_registry_name, key="status", value="best")
latest_version = mlflow.search_model_versions(filter_string=f"name='{model_registry_name}'")[0]
if accuracy > best_model_accuracy:
if best_model_version is not None:
client.set_model_version_tag(model_registry_name, best_model_version, "status", "previous_best")
client.set_model_version_tag(model_registry_name, latest_version, "status", "best")
print(f"New model with accuracy {accuracy} is now the best model.")
else:
print(f"New model with accuracy {accuracy} did not outperform the current best model with accuracy {best_model_accuracy}.")
Gjør prediksjoner med den beste modellen!
For å gjøre prediksjoner med den beste modellen i MLFlow, så er det eneste vi trenger å hente ut modellen tagget med “best” på nesten nøyaktig samme måte som under treningen.
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
model_version, _ = get_best_model_version(MODEL_REGISTRY_NAME, "status", "best")
model = mlflow.keras.load_model(model_version.source)
predictions = model.predict(data)Supert! Nå har vi mye større kontroll på hvordan modelltreningene våre gjør det over tid! Dersom vi ønsker å prøve ut forskjellige parametere, input variabler eller treningslengde, kan disse fint også logges sammen med evalueringsmetrikkene. Her får vi altså en omfattende oversikt over hvilke modeller som gjør det best, og hvilke parametere vi har brukt for å oppnå disse resultatene 🏋️

Ressurser
Kildekode: https://github.com/stianmogen/mlflow-gcp
MLflow: https://www.mlflow.org/docs/latest/introduction/index.html
Cloud Run: https://cloud.google.com/run/docs/deploying
Blogginnlegg — MLflow med CD: https://medium.com/@andrevargas22/how-to-launch-an-mlflow-server-with-continuous-deployment-on-gcp-in-minutes-7d3a29feff88

